
|
|
|
|
Главная --> Промиздат --> Интерполирование поверхности Декластеризация данных, отобранных с различной густотой Существует два способа выполнить декластеризацию ваших данных: методом подбора гри-да и методом полигонов Вороного. Выборка должна быть сформирована таким образом, чтобы быть репрезентативной для всей поверхности. Однако, часто выборка осуществляется в местах с наибольшей концентрацией точек, что приводит к искажению отображения поверхности. Декластеризация учитывает неравномерное расположение опорных точек путем их соответствующего взвешивания, что приводит к возможности более точного построения поверхности. Подсказка Использование декластеризации Декластеризация может быть применена только в том случае, если используется преобразование по методу нормальных меток. Чтобы иметь возможность воспользоваться преобразованием по методу нормальных меток, выбирайте методг вероятностного, простого или дизъюнктивного кригинга/кокригинга. Выполнение декластеризации по методу ячейки 1. В диалоге Выберите входные данные и метод выберите кри-гинг или кокригинг. 2. Выберите один из методов кригинга или кокригинга: вероятностный, дизъюнктивный, или простой. 3. В диалоге Преобразование выберите преобразование по методу нормальн1х меток. 4. Выберите опцию Декластери-зация перед преобразованием. 5. Нажмите Далее. 6. В меню Выбор набора данных определите набор данных, который вы хотите отобразить (только для кокригинга). 7. Задайте необходимые параметры. 8. Выбирайте различные закладки для того, чтобы просмотреть диаграммы, отражающие изменение выборки в зависимости от Размера ячейки, Анизотропии и Угла наклона ячейки. 9. Измените размер ячейки, анизотропию, смещение и угол наклона ячейки, чтобы определить экстремум графика. 10. Или из меню Метод декласте-ризации выберите Полигоны, чтобы отобразить полигон:, по которым будет выполняться декластеризация. 11. Нажмите Далее. ►   12. Из меню Аппроксимация выберите метод аппроксимации, определите параметры, и отметьте опцию Плотность вероятности или Кумулятивное распределение в диалоге Преобразование по методу нормальных меток. Нажмите Далее. 13. В диалоге Моделирование ва-риограммы/ковариации задайте требуемые параметры и нажмите Далее. 14. Определите параметры в диалоге Поиск соседства и нажмите Далее. 15. Изучите результаты в диалоге Перекрестная проверка и нажмите Готово. 16. В диалоге Информация о результирующем слое нажмите OK. Иногда вам может понадобиться впчесть тренд поверхности из данных и применить кригинг или кокригинг для данных с вычтенным трендом, которые носят название остатков. Рассмотрим аддитивную модель, Z(s) = m(s) + e(s) где m(s) - некая детерминистская поверхность (которая носит название тренда) и e (s) - пространственно коррелированная ошибка. Теоретически, тренд зафиксирован, что означает, что если вы будете моделировать данные снова и снова, тренд меняться не будет. Однако, вы увидите флуктуации в моделируемых поверхностях, что вызвано начилием автокоррелированных случайных ошибок. Обычно тренд в пространстве меняется постепенно, в то время как случайные ошибки меняются быстрее. Метеорологическим примером тренда может быть наблюдаемое вами (и известное из теории) постепенное изменение температуры в зависимости от широты. Однако, метеорологические наблюдения для каждого конкретного дня отражают локальные отклонения, которые возникают вследствие движения фронтальных масс, различий в подстилающей поверхности, облачности, и т.п. и являются труднопредсказуемыми, следовательно, локальные отклонения моделируются как автокоррелирующие. К сожалению, нет никакого магического способа однозначно разложить данные на тренд и случайные ошибки. Изложенные далее соображения могут помочь вам в этом процессе. На следующем рисунке показаны данные, полученные при помощи двух моделей. Одна из них - ординарный кригинг, где Z(s) = m + e (s) и ошибки e (s) коррелируют. Процесс имеет среднее m = 0 и экспоненциальную вариограмму. Другой набор данных был смоделирован с использованием универсального кригинга: m (s) = b0 + b 1х (s) + b2x2 (s) (сплошная линия на рисунке); но ошибки бпли независимы, со средним значением, равнхм 0, и дисперсией, равной 1. Как видите, трудно определить, какие точки соответствуют какой модели (синие точки соответствуют значениям, полученным при использовании ординарного кригинга, а красные точки - универсального кригинга с независимыми ошибками). Пространственная автокорреляция может позволить строить различнхе поверхности интерполяции, и этот пример демонстрирует, что 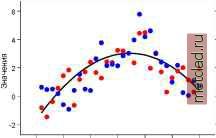 0 5 10 15 20 25 30 часто может бпть трудно впбрать между моделями, основаннхми только на данных. В целом, вы должны придерживаться ординарного кригинга до тех пор, пока у вас не возникнут серьезные причины для вычитания поверхности тренда. Это вызвано тем, что лучше использовать простые модели. Если вы вычитаете поверхность тренда, параметров, которые вам необходимо оценить, больше. Двумерная поверхность второй степени к отсекающему параметру добавляет еще пять параметров, требующих оценки. Чем большее количество параметров оценивается, тем менее точной становится модель. Однако, в некоторых случаях пространственные координаты служат как заменитель для некоего известного тренда в данных. Например, урожайность может меняться в зависимости от широты-причиной этого являются не сами координаты, а такие показатели, меняющиеся с широтой, как температура, влажность, осадки и т.д. В данном случае, вычитание поверхностей тренда может иметь смысл. Повторим снова, что чем проще поверхность (полином первой или второй степени), тем лучше. В модуле Geostatistical Analyst возможно также применение локального полиномиального сглаживания как опции втчитания тренда. Существует реальная опасность слишком точного подбора данных при использовании трендов и сохранении слишком маленькой дисперсии в отклонениях, что приводит к ошибкам и некорректному учету неопределенности интерполяции. При применении моделей, учитхвающих тренд, всегда проверяйте их с использованием перекрестной проверки и особенно проверки.
|