
|
|
|
|
Главная --> Промиздат --> Интерполирование поверхности Изучение различных моделей кригинга Методы кригинга полагаются на математические и статистические модели. Учет вероятности в статистической модели отличает методы кригинга от детерминистских методов, описанных в Главе 5, Детерминистские методы интерполяции пространственных данных. При кригинге вы связываете некую вероятность с выполняемой вами интерполяцией; это означает, что значения не могут быть получены по статистической модели абсолютно точно. Рассмотрим пример с измеренными значениями содержания нитратов в почве. Очевидно, что даже при наличии большой выборки, вы не сможете вычислить точное значение содержания нитратов в какой-нибудь конкретной точке, в которой измерения не проводились. Следовательно, вы можете только попытаться проинтерполировать ее значение, и при этом оценить ошибку интерполяции. Методы кригинга основываются на понятии корреляции. Корреляцию часто определяют как тенденцию двух типов переменных к взаимозависимости. Например, уровень цен на фондовой бирже имеет тенденцию к позитивным изменениям при низком спросе, поэтому говорят, что они обратно коррелируют. Кроме того, можно утверждать, что уровень цен на бирже имеет положительную корреляцию, что означает, что он коррелирует сам с собой. На фондовом рынке два значения цены будут иметь тенденцию к совпадению, если они относятся к двум датам, следующим одна за другой, в отличие от дат, которые разделяет год. Величина, при которой корреляция исчезает, может быть выражена как функция расстояния. На следующем рисунке корреляция показана как функция расстояния. Это определяющая характеристика геостатистики. В классической статистике предполагается, что наблюдения являются независимыми; следовательно наблюдения не коррелируют между собой. В геостатистике, информация о положении точек наблюдения в пространстве позволяет вам вычислить расстояния между точками наблюдения и смоделировать корреляцию как функцию расстояния. АВТОКОРРЕЛЯЦИЯ  Расстояние Также обратите внимание, что в целом, цены фондового рынка растут, и такая тенденция носит название тренда . Для геостатистических данных, вы оперируете теми же терминами, которые могут быть выражены простой математической формулой, Z(s) = (3) + г(з), где Z(s) - интересующая нас переменная, разложенная на детерминистский тренд m (s), и случайнхе, коррелирующие ошибки e (s). Символ s просто указхвает на положение точки; то есть обладает координатами х- (долгота) и у- (широта). Различные варианты этой формулы образуют основу для различных типов кригинга, поэтому она стоит усилий, потраченных на ознакомление с ней. Не имеет значения, насколько сложным в модели является тренд, - составляющая m(s) все равно не сможет дать точнхх проинтерполированных значений. В этом случае, делаются некоторые допущения относительно ошибки e ( s); а именно, предполагается, что среднее значение ошибки будет равно 0 и корреляция между e (s) и e (s+h) не зависит от действительного положения точки s, а только от взаимного расположения двух точек, или расстояния h. Это необходимо для оценки функции корреляции. Например, для примера на следующем рисунке, предполагается, что случайные ошибки для пар точек, соединенных стрелками, будут одинаково коррелировать. ,.si+h Далее, изучите тренд. Он может быть простой константой; то есть, m(s) = m для всех точек , и если m известно, это и является моделью, на которой основан ординарный кригинг. Он также может быть представлен линейной функцией самих пространственных координат, например, m(s) = b0 + bjX + b2y + b3x2 + by2 + b5xy, где поверхность тренда представлена полиномом второй степени и является линейной регрессией пространственных координат x и y. Тренды, которые варьируют, и для которых коэффициенты регрессии неизвестны, образуют модели универсального кригинга. Если же полностью известен тренд (т.е., известны все параметры и ковариаты), независимо от того, является он постоянным или нет, он образует модель для простого кригинга. Теперь рассмотрим левую часть вхражения, Z(s) =m (s) +e (s). Вы можете выполнить преобразования значения Z(s). Например, вы можете изменить его на индикаторную переменную, то есть значениям Z(s) будет присвоен 0, если они ниже некоторой величины (например, 0.12 ppm для концентрации озона) или 1, если они превхшают какое-либо значение. Затем, вы можете спрогнозировать вероятность того, что значения Z(s) - выше порогового, и такая интерполяция будет носить название индикаторного кригинга. Вы можете также выполнить общие преобразования для значений Z( s), назвав их функцией /i(Z(s.)) для i-той переменной. Из функций переменнгх вы можете образовать интерполяторы; например, если вы хотите найти значение показателя в точке s0, вы формируете интерполятор дизъюнктивного кригинга из значений функции (Z (s0)) с использованием данных функции /i(Z(si)). В модуле Geostatistical Analyst, функция g - либо индикаторное преобразование, либо отсутствие преобразования. И наконец, рассмотрим случай, когда у вас есть больше одного типа переменнхх, и вы формируете модели (s) = m. (s) + e. (s) для j-того типа переменной. Вы можете учесть различные тренды для каждой переменной, и помимо этого, автокорреляцию для ошибок ej (s); существует также взаимная корреляция между ошибками ej (s) и ek (s) для двух типов переменных. Например, вы можете учесть взаимную корреляцию между двумя переменными, такими как концентрация озона и определенного вещества, и они необязательно должны быть измерены в одних и тех же точках. Модели, основанные на более чем одной переменной, образуют базу для кокригинга. Вы можете создать индикаторную переменную для значений Z( s) и, если вы будете вычислять искомое значение с использованием исходных непре-образованных даннхх Z(s) в модели кокригинга, вы получите вероятностный кригинг. Если изначально у вас есть более одной переменной, для которой вы хотите интерполировать поверхность, вы можете рассматривать ординарный кокригинг, универсальный кокригинг, простой кокригинг, индикаторный кок-ригинг, вероятностный кокригинг и дизъюнктивный кокригинг, как многовариантные расширения различнхх типов кригинга, описанных ранее. Изучение типов результирующих поверхностей Кригинг и кокригинг - методы интерполяции, и их цель - построить поверхность предполагаемых (проинтерполированных) значений. Вы можете также захотеть получить ответ на вопрос: Насколько точны полученные значения? Можно создать три типа карт предполагаемых значений, и два из них имеют связанные с ними стандартные ошибки. На предыдущих страницах, методы кригинга были сгруппированы по типу моделей, которые они используют; в этом разделе мы приводим их классификацию по целям использования. Рассмотрим следующий рисунок. Предполагается, что искомые значения в трех точках подчиняются нормальному закону распределения. 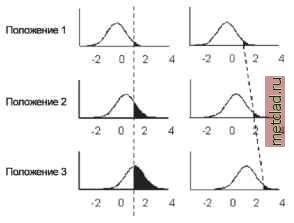 можно построить карту вероятности для всей поверхности. Рассмотрим три правых рисунка. Квантиль с пятью процентами вероятности в правой части распределения будет равен значению, полученному при пересечении пунктирной линией оси х. Снова заметим, что распределение проинтерполированных значений меняется с каждой точкой. Таким образом, сохраняя значение вероятности постоянным, для всей поверхности можно построить карту квантилей. Для карт проинтерполированных значений и для карт вероятности могут быть созданы карты стандартных ошибок. В таблице даны различные методы и результирующие карты, которые могут быть построены с их помощью, а также основные ограничения для каждого из методов.
* Требует многомерного нормального распределения + Требует парного двумерного нормального распределения В таком случае, искомое значение будет находиться в центре каждой кривой, и можно построить карту проинтерполированных значений для всей поверхности. Рассмотрим три левхх рисунка. Вероятность того, что значение в искомой точке превысит пороговое значение, к примеру, равное 1, равна площади под кривой справа от пунктирной линии. Распределение проин-терполированнхх значений меняется с добавлением каждой точки. Таким образом, сохраняя пороговое значение постоянным,
|